
 汉王OCR文字识别工具历经多次迭代升级,在继承尚书系列核心功能基础上,实现智能化图像转文字服务。作为光学字符识别领域的标杆产品,其通过扫描设备或数码影像快速提取印刷体文字,有效解决传统纸质文档电子化难题。
汉王OCR文字识别工具历经多次迭代升级,在继承尚书系列核心功能基础上,实现智能化图像转文字服务。作为光学字符识别领域的标杆产品,其通过扫描设备或数码影像快速提取印刷体文字,有效解决传统纸质文档电子化难题。
技术演进
光学字符识别技术自1929年德国专利问世至今,经历了从实验室理论到商业应用的跨越式发展。该工具采用前沿算法架构,支持PDF文件批量转换为可编辑的RTF/TXT格式,兼容TIFF/JPEG/GIF等多种图像格式处理。用户通过角度校正、版面分析、快捷键识别三步操作即可完成文档数字化。
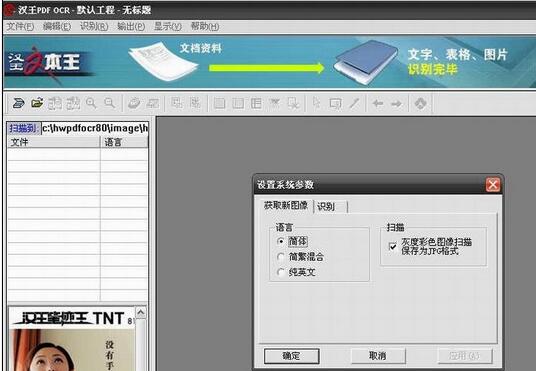
核心处理流程
图像预处理系统采用智能二值化技术,将彩色图像转化为高对比度黑白文档,配合自主研发的噪声过滤算法,有效消除拍摄产生的杂质干扰。倾斜校正模块可自动检测并修正±15度范围内的图像偏转,确保文字识别基准线准确。
多语言识别引擎在处理纯中文或纯英文文档时展现卓越性能,字词识别准确率可达98%以上。针对复杂排版文档,系统通过动态版面分析技术自动划分段落区域,保持原始文档的版式结构,实现从图像到可编辑文档的无损转换。
用户实测反馈
「文档管理效率提升显著」网友[墨染书香]评价:"处理会议纪要扫描件时,表格识别效果超出预期,省去大量手动录入时间"
「学术研究好帮手」用户[星辰大海]分享:"古籍文献数字化转换准确率高,生僻字识别功能表现优异"
「商务办公优选」企业用户[云端办公]反馈:"批量处理合同扫描件效率提升3倍,但混合排版文档需二次校对"
智能识别进阶
系统采用深度学习框架优化字符切割算法,有效解决连笔字、模糊字符的识别难题。后处理模块集成语言模型校验功能,通过上下文语义分析自动修正识别误差,确保输出内容的逻辑连贯性。特别设计的批处理模式支持百页文档连续转换,满足企业级文档数字化需求。

 鼠标速度切换工具高效调节方案v3.4.5
05-13 / 1.92MB
鼠标速度切换工具高效调节方案v3.4.5
05-13 / 1.92MB
 Office Tool Plus一站式Office部署方案v10.0.2.6 最新版
05-13 / 8.10MB
Office Tool Plus一站式Office部署方案v10.0.2.6 最新版
05-13 / 8.10MB
 超星阅读器电子书阅读工具免费下载v5.8.0.25674
05-13 / 26.17MB
超星阅读器电子书阅读工具免费下载v5.8.0.25674
05-13 / 26.17MB
 WPS2020办公软件全面评测
05-13 / 103.00MB
WPS2020办公软件全面评测
05-13 / 103.00MB
 2345好压免费高效压缩工具推荐v6.3.1.11134
05-12 / 23.13 MB
2345好压免费高效压缩工具推荐v6.3.1.11134
05-12 / 23.13 MB
 Visual Studio Code中文版免费开发工具下载Visual Studio Code(源代码编辑器)正式版下载 v1.74.3.0 中文版
05-12 / 75.92MB
Visual Studio Code中文版免费开发工具下载Visual Studio Code(源代码编辑器)正式版下载 v1.74.3.0 中文版
05-12 / 75.92MB
